Deepseek-R1的出奇发达激勉了世俗重视,但其锻真金不怕火圭表长久未尝公开。天然Deepseek的模子已开源,但其锻真金不怕火圭表、数据和剧本等环节信息仍未对外裸露。
凭据Deepseek公布的信息,许多东说念主以为,只须锻真金不怕火更大范围的模子,才能果然解析强化学习(RL)的威力。关连词,锻真金不怕火大模子需要强大的规划资源,让路源社区退避三舍。现在的使命(如TinyZero)仅在简便任务上复现了所谓的“Ahamoment”,或者仅提供锻真金不怕火基础设施和数据(如OpenR)。
一个由伯克利团队领衔的延续小组建议了一个果敢的成见:能否用仅1.5B参数的小模子,以低老本复现Deepseek的锻真金不怕火秘方?他们发现,简便复现Deepseek-R1的锻真金不怕火圭表需要巨大老本,即使在最小的模子上也需要数十万好意思元。但通过一系列锻真金不怕火手段,团队见效将老本大幅镌汰,最终仅用4500好意思元,就在一个1.5B参数的模子上复现了Deepseek的环节锻真金不怕火圭表。
他们的效果——DeepScaleR-1.5B-Preview,基于Deepseek-R1-Distilled-Qwen-1.5B模子,通过强化学习(RL)微调,已矣了惊东说念主的43.1%Pass@1准确率,擢升了14.3%,并在AIME2024竞赛中超越了O1-Preview。
这一效果不仅龙套了“大模子才能执意”的固有融会,更展示了RL在袖珍模子中的无穷可能。
更进军的是,伯克利团队开源了统统的锻真金不怕火秘方,包括模子、数据、锻真金不怕火代码和锻真金不怕火日记,为鼓舞LLM强化学习锻真金不怕火的普及迈出了进军一步。

这项延续已经公布,受到网友世俗好评,有网友暗意:「DeepScaleR-1.5B-Preview正在撼动东说念主工智能畛域。」
「DeepScaleR草创了AI扩张的新期间。」

「开源界又赢了一局。」

还有东说念主盛赞:「这才是延续者想要的东西。」
1.小模子的反击:DeepScaleR的狡饰
挑战RL的极限
强化学习一直被视为大模子的“专属火器”,闲雅的规划老本让好多东说念主退避三舍。延续团队发现,假如径直复现Deepseek-R1的截止(32K高下文长度,8000锻真金不怕火步数),即使在一个1.5B的小模子上,需要的A100GPU时长高达70,000小时。但延续团队并未着重,他们建议了一种高明的政策,让RL的锻真金不怕火老本镌汰至旧例圭表的5%,最终只用了3800A100GPU小时和4500好意思元,就在1.5B的模子上锻真金不怕火出了一个超越OpenAIo1-preview的模子,DeepScaleR的狡饰,在于建议了一个迭代式高下文扩张的锻真金不怕火政策。
迭代式高下文扩张:小步快跑,突破瓶颈
在RL锻真金不怕火中,高下文窗口的礼聘至关进军。礼聘一个比拟长的高下文会导致锻真金不怕火变慢,而礼聘一个短的高下文则可能导致模子莫得裕如的高下文去念念考繁重的问题。
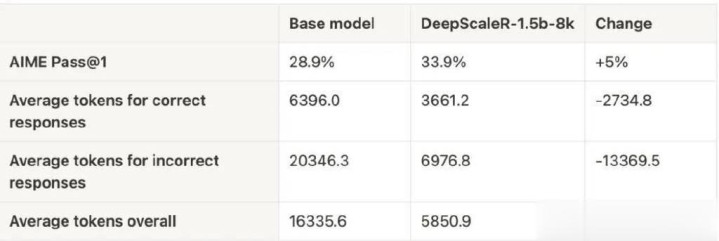
延续团队在锻真金不怕火前进行了先验测试,迪士尼彩乐园平台如何发现症结谜底的平均长度是正确谜底的3倍。这标明,要是径直在大窗口上进行锻真金不怕火,不仅锻真金不怕火速率慢,效果也可能受限,因为有用锻真金不怕火的字符(token)数目较少。
基于这个发现,因此他们经受了迭代式高下文扩张政策:
1.8K高下文窗口:模子先在较短的高下文中简化我方的推理,精进推理手段。
2.扩张至16K&24K:渐渐加大窗口,让模子稳妥更复杂的数学推理任务。
这种政策证实注解是有用的——在第一轮8K高下文锻真金不怕火后,模子的平均回话长度从9000字符降至3000字符,而AIME测试集上的正确率提高了5%。跟着高下文窗口扩张至16K和24K,模子更通俗的回话气象使锻真金不怕火时辰至少擢升了两倍。
数据集:四万说念数学难题的试真金不怕火
团队全心构建了一套高质料的数学锻真金不怕火集,包括:
AIME(1984-2023)
AMC(2023年前)
Omni-MATH&Still数据集
数据筛选的环节要领:
1.谜底索求:欺骗gemini-1.5-pro-002自动索求圭臬谜底。
2.去重:经受sentence-transformers/all-MiniLM-L6-v2进行语义去重,幸免数据混浊。
3.过滤弗成评分题目:确保锻真金不怕火数据的高质料,使模子能够专注于可考据的谜底。
奖励函数:精确激励模子卓绝
传统的RL锻真金不怕火时常使用流程奖励模子(PRM),但容易导致“奖励花费”,即模子学会取巧而非果然优化推理才略。为了处置这一问题,延续团队礼聘了跟Deepseek-R1一样的截止奖励模子(ORM),严格按照谜底正确性和形势进行评分,确保模子果然擢升推理才略。
2.执行截止:数据不会说谎
在多项数学竞赛基准测试中,DeepScaleR-1.5B-Preview展现了惊东说念主的实力:
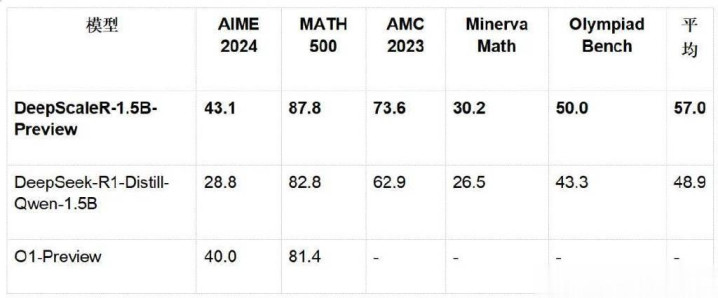
环节突破点:
1.DeepScaleR在AIME2024上超越O1-Preview,证实注解了RL在小模子上的可行性。
2.在统统测试延续,DeepScaleR的平均发达远超基础模子,展现了强化学习的巨大后劲。
3.环节发现:为什么DeepScaleR能见效?
(1)RL并非大模子专属,小模子雷同能崛起
DeepScaleR的见效龙套了强化学习只可用于大模子的迷念念。延续团队通过高质料的SFT数据,让1.5B小模子的AIME准确率从28.9%擢升至43.1%,证实注解了小模子也能通过RL已矣飞跃。
(2)迭代式高下文扩张:比暴力锻真金不怕火更高效
径直在24K高下文窗口中进行强化学习,效果远不如渐渐扩张。先学短推理,再扩张长推理,不错让模子更踏实地稳妥复杂任务,同期减少锻真金不怕火老本。
4.论断:RL的新纪元
DeepScaleR-1.5B-Preview的见效,不仅展示了小模子在强化学习中的无穷后劲,也证实注解了高效锻真金不怕火政策的进军性。团队但愿通过开源数据集、代码和锻真金不怕火日记,鼓舞RL在LLM推理中的世俗应用。
理查兹说道:“这有点荒谬,不是吗?C罗是一名传奇,在理查利森眼中内马尔非常出色,但你为什么要将他纹在身上?”
下一步,他们计算在更大范围的模子上复现这一政策,并邀请社区共同探索RL的新可能。
省略迪士尼彩乐园注册,下一个挑战OpenAI的模子,就藏在这么一个小小的执行之中。